TVCG 2024
Lara Lenz, Andreas Fender, Julia Chatain, Christian Holz
Asynchronous digital communication is a widely applied and well-known form of information exchange. Most pieces of technology make use of some variation of asynchronous communication systems, be it messaging or email applications. This allows recipients to process digital messages immediately (synchronous) or whenever they have time (asynchronous), meaning that purely digital interruptions can be mitigated easily. Mixed Reality systems have the potential to not only handle digital interruptions but also interruptions in physical space, e.g., caused by co-workers in workspaces or learning environments. However, the benefits of such systems previously remained untested in the context of Mixed Reality. We conducted a user study (N=26) to investigate the impact that the timing of task delivery has on the participants' performance, workflow, and emotional state. Participants had to perform several cognitively demanding tasks in a Mixed Reality workspace. Inside the virtual workspace, we simulated in-person task delivery either during tasks (i.e., interrupting the participant) or between tasks (i.e., delaying the interruption). Our results show that delaying interruptions has a significant impact on subjective metrics like the perceived performance and workload. |
ACM UIST 2023
Andreas Fender, Derek Alexander Witzig, Max Moebus, Christian Holz
When learning to play an instrument, it is crucial for the learner's muscles to be in a relaxed state when practicing. Identifying, which parts of a song lead to increased muscle tension requires self-awareness during an already cognitively demanding task. In this work, we investigate unobtrusive pressure sensing for estimating muscle tension while practicing songs with the guitar. First, we collected data from twelve guitarists. Our apparatus consisted of three pressure sensors (one on each side of the guitar pick and one on the guitar neck) to determine the sensor that is most suitable for automatically estimating muscle tension. Second, we extracted features from the pressure time series that are indicative of muscle tension. Third, we present the hardware and software design of our PressurePick prototype, which is directly informed by the data collection and subsequent analysis. |
ACM CHI 2023
Andreas Fender, Thomas Roberts, Tiffany Luong, Christian Holz
Digital painting interfaces require an input fidelity that preserves the artistic expression of the user. Drawing tablets allow for precise and low-latency sensing of pen motions and other parameters like pressure to convert them to fully digitized strokes. A drawback is that those interfaces are rigid. While soft brushes can be simulated in software, the haptic sensation of the rigid pen input device is different compared to using a soft wet brush on paper. We present InfinitePaint, a system that supports digital painting in Virtual Reality on real paper with a real wet brush. We use special paper that turns black wherever it comes into contact with water and turns blank again upon drying. A single camera captures those temporary strokes and digitizes them while applying properties like color or other digital effects. We tested our system with artists and compared the subjective experience with a drawing tablet. |
ACM UIST 2022
Guy Luethi, Andreas Fender, Christian Holz
We present DeltaPen, a pen device that operates on passive surfaces without the need for external tracking systems or active sensing surfaces. DeltaPen integrates two adjacent lens-less optical flow sensors at its tip, from which it reconstructs accurate directional motion as well as yaw rotation. DeltaPen also supports tilt interaction using a built-in inertial sensor. A pressure sensor and high-fidelity haptic actuator complements our pen device while retaining a compact form factor that supports mobile use on uninstrumented surfaces. We present a processing pipeline that reliably extracts fine-grained pen translations and rotations from the two optical flow sensors. To asses the accuracy of our translation and angle estimation pipeline, we conducted a technical evaluation in which we compared our approach with ground-truth measurements of participants' pen movements during typical pen interactions. We conclude with several example applications that leverage our device's capabilities. Taken together, we demonstrate novel input dimensions with DeltaPen that have so far only existed in systems that require active sensing surfaces or external tracking. |
ACM CHI 2022
(Best paper award)
Andreas Fender, Christian Holz
Additional links: [Full scenario] [Conference presentation] [Explainer video]
Mixed Reality is gaining interest as a platform for collaboration and focused work to a point where it may supersede current office settings in future workplaces. At the same time, we expect that interaction with physical objects and face-to-face communication will remain crucial for future work environments, which is a particular challenge in fully immersive Virtual Reality. In this work, we reconcile those requirements through a user's individual Asynchronous Reality, which enables seamless physical interaction across time. When a user is unavailable, e.g., focused on a task or in a call, our approach captures co-located or remote physical events in real-time, constructs a causality graph of co-dependent events, and lets immersed users revisit them at a suitable time in a causally accurate way. Enabled by our system AsyncReality, we present a workplace scenario that includes walk-in interruptions during a person's focused work, physical deliveries, and transient spoken messages. We then generalize our approach to a use-case agnostic concept and system architecture. We conclude by discussing the implications of an Asynchronous Reality for future offices. |
  Video co-edited with Paul Streli Video co-edited with Paul Streli
Paul Streli, Jiaxi Jiang, Andreas Fender, Manuel Meier, Hugo Romat, Christian Holz
Despite the advent of touchscreens, typing on physical keyboards remains most efficient for entering text, because users can leverage all fingers across a full-size keyboard for convenient typing. As users increasingly type on the go, text input on mobile and wearable devices has had to compromise on full-size typing. In this paper, we present TapType, a mobile text entry system for full-size typing on passive surfaces—without an actual keyboard. From the inertial sensors inside a band on either wrist, TapType decodes and relates surface taps to a traditional QWERTY keyboard layout. The key novelty of our method is to predict the most likely character sequences by fusing the finger probabilities from our Bayesian neural network classifier with the characters’ prior probabilities from an n-gram language model. In our online evaluation, participants on average typed 19 words per minute with a character error rate of 0.6% after 30 minutes of training. Expert typists thereby consistently achieved more than 25 WPM at a similar error rate. We demonstrate applications of TapType in mobile use around smartphones and tablets, as a complement to interaction in situated Mixed Reality outside visual control, and as an eyes-free mobile text input method using an audio feedback-only interface. |
ACM CHI 2021
Andreas Fender, Diego Martinez Plasencia, Sriram Subramanian
Acoustic levitation is gaining popularity as an approach to create physicalized mid-air content by levitating different types of levitation primitives. Such primitives can be independent particles or particles that are physically connected via threads or pieces of cloth to form shapes in mid-air. However, initialization (i.e., placement of such primitives in their mid-air target locations) currently relies on either manual placement or specialized ad-hoc implementations, which limits their practical usage. We present ArticuLev, an integrated pipeline that deals with the identification, assembly and mid-air placement of levitated shape primitives. We designed ArticuLev with the physical properties of commonly used levitation primitives in mind. It enables experiences that seamlessly combine different primitives into meaningful structures (including fully articulated animated shapes) and supports various levitation display approaches (e.g., particles moving at high speed). In this paper, we describe our pipeline and demonstrate it with heterogeneous combinations of levitation primitives. |
 Storyboard of video by Christian Holz Storyboard of video by Christian Holz
Manuel Meier, Paul Streli, Andreas Fender, Christian Holz
In this paper, we bring rapid touch interaction on surfaces to Virtual Reality. Current systems capture input with cameras, for which touch detection remains a core challenge, often leaving free-hand mid-air interaction and controllers as viable alternatives for input. We present TapID, a wrist-based system that complements optical hand tracking with inertial sensing to detect touch events on surfaces - the input modality that users have grown used to on phones and tablets. TapID embeds a pair of inertial sensors in a flexible strap, one at either side of the wrist; from the combination of registered signals, TapID reliably detects surface touch events and, more importantly, identifies the finger used for touch, which we fuse with optically tracked hand poses to trigger input in VR. We evaluated TapID in a series of user studies on event-detection accuracy (F1 = 0.997) and finger-identification accuracy (within-user: F1 = 0.93; cross-user: F1 = 0.91 after 10 refinement taps and F1 = 0.87 with no refinement) in a seated table scenario. We conclude with a series of applications that complement hand tracking with touch input, including UI control, rapid typing, and surface gestures. |
 Video edited by Hugo Romat Video edited by Hugo Romat
Hugo Romat, Andreas Fender, Manuel Meier, Christian Holz
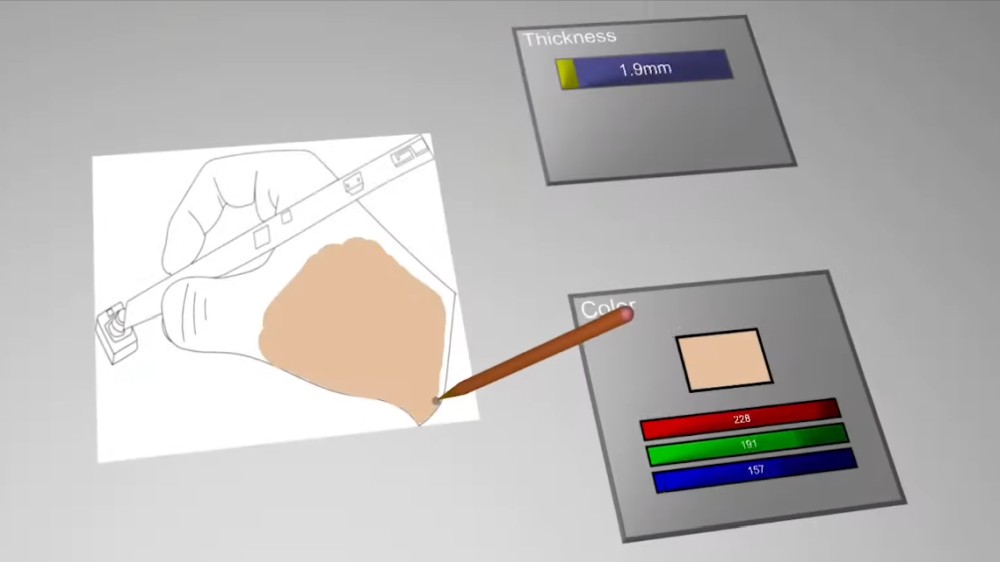
Digital pen interaction has become a first-class input modality for precision tasks such as writing, annotating, and drawing. In Virtual Reality, however, input is largely detected using cameras which does not nearly reach the fidelity we achieve with analog handwriting or the spatial resolution required to enable fine-grained on-surface input.
We present FlashPen, a digital pen for VR whose sensing principle affords accurately digitizing hand-writing and fine-grained 2D input for manipulation. We combine absolute camera tracking with relative motion sensing from an optical flow sensor. In this paper, we describe our prototype, a user study and several application prototypes. |
ACM ISS 2019
(Best application paper award)
Joao Belo, Andreas Fender, Tiare Feuchtner, Kaj Groenbaek
We present a digital assistance approach for applied metrology on near-symmetrical objects. In manufacturing, systematically measuring products for quality assurance is often a manual task, where the primary challenge for the workers lies in accurately identifying positions to measure and correctly documenting these measurements. This paper focuses on a use-case, which involves metrology of small near-symmetrical objects, such as LEGO bricks. We aim to support this task through situated visual measurement guides. Aligning these guides poses a major challenge, since fine grained details, such as embossed logos, serve as the only feature by which to retrieve an object's unique orientation. We present a two-step approach, which consists of (1) locating and orienting the object based on its shape, and then (2) disambiguating the object's rotational symmetry based on small visual features. We apply and compare different deep learning approaches and discuss our guidance system in the context of our use case. |
ACM ISS 2019
Andreas Fender, Joerg Mueller
We present SpaceState, a system for designing spatial user interfaces that react to changes of the physical layout of a room. SpaceState uses depth cameras to measure the physical environment and allows designers to interactively define global and local states of the room. After designers defined states, SpaceState can identify the current state of the physical environment in real-time. This allows applications to adapt the content to room states and to react to transitions between states. Other scenarios include analysis and optimizations of work flows in physical environments. We demonstrate SpaceState by showcasing various example states and interactions. Lastly, we implemented an example application: A projection mapping based tele-presence application, which projects a remote user in the local physical space according to the current layout of the space. |
ACM ISS 2018
Andreas Fender, Joerg Mueller
We present Velt, a flexible framework for multi RGB-D camera systems. Velt supports modular real-time streaming and processing of multiple RGB, depth and skeleton streams in a camera network. RGB-D data from multiple devices can be combined into 3D data like point clouds. Furthermore, we present an integrated GUI, which enables viewing and controlling all streams, as well as debugging and profiling performance. The node-based GUI provides access to everything from high level parameters like frame rate to low level properties of each individual device. Velt supports modular preprocessing operations like downsampling and cropping of streaming data. Furthermore, streams can be recorded and played back. This paper presents the architecture and implementation of Velt. |
 Video fully created by Soeren Qvist Jensen Video fully created by Soeren Qvist Jensen
Soeren Qvist Jensen, Andreas Fender, Joerg Mueller
We present Inpher, a virtual reality system for setting physical properties of virtual objects using mid-air interaction. Users simply grasp virtual objects and mimic their desired physical movement. The physical properties required to fulfill that movement will then be inferred directly from that motion. We provide a 3D user interface that does not require users to have an abstract model of physical properties. Our approach leverages users' real world experiences with physics. We conducted a bodystorming to investigate users' mental model of physics. Based on our iterative design process, we implemented techniques for inferring mass, bounciness and friction. We conducted a case study with 15 participants with varying levels of physics education. The results indicate that users are capable of demonstrating the required interactions and achieve satisfying results. |
ACM CHI 2018
Andreas Fender, Philipp Herholz, Marc Alexa, Joerg Mueller
We present OptiSpace, a system for the automated placement of perspectively corrected projection mapping content. We analyze the geometry of physical surfaces and the viewing behavior of users over time using depth cameras. Our system measures user view behavior and simulates a virtual projection mapping scene users would see if content were placed in a particular way. OptiSpace evaluates the simulated scene according to perceptual criteria, including visibility and visual quality of virtual content. Finally, based on these evaluations, it optimizes content placement, using a two-phase procedure involving adaptive sampling and the covariance matrix adaptation algorithm. With our proposed architecture, projection mapping applications are developed without any knowledge of the physical layouts of the target environments. Applications can be deployed in different uncontrolled environments, such as living rooms and office spaces. |
ACM UIST 2017
Andreas Fender, David Lindlbauer, Philipp Herholz, Marc Alexa, Joerg Mueller
We present HeatSpace, a system that records and empirically analyzes user behavior in a space and automatically suggests positions and sizes for new displays. The system uses depth cameras to capture 3D geometry and users' perspectives over time. To derive possible display placements, it calculates volumetric heatmaps describing geometric persistence and planarity of structures inside the space. It evaluates visibility of display poses by calculating a volumetric heatmap describing occlusions, position within users' field of view, and viewing angle. Optimal display size is calculated through a heatmap of average viewing distance. Based on the heatmaps and user constraints we sample the space of valid display placements and jointly optimize their positions. This can be useful when installing displays in multi-display environments such as meeting rooms, offices, and train stations. |
ACM ISS 2017
(Best application paper award)
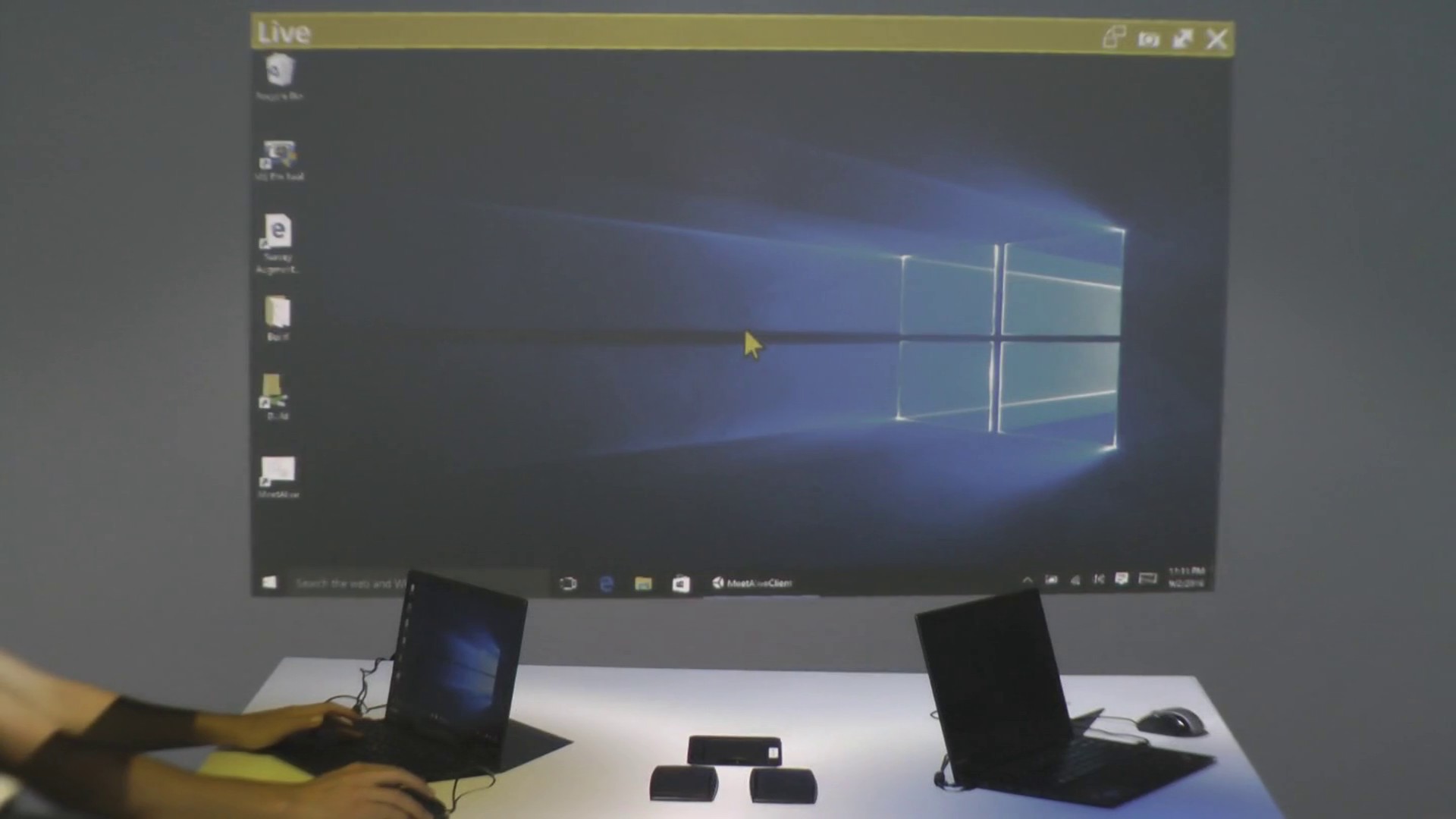
Andreas Fender, Hrvoje Benko, Andy Wilson
MeetAlive combines multiple depth cameras and projectors to create a room-scale omni-directional display surface designed to support collaborative face-to-face group meetings. With MeetAlive, all participants may simultaneously display and share content from their personal laptop wirelessly anywhere in the room. MeetAlive gives each participant complete control over displayed content in the room. This is achieved by a perspective corrected mouse cursor that transcends the boundary of the laptop screen to position, resize, and edit their own and others' shared content. MeetAlive includes features to replicate content views to ensure that all participants may see the actions of other participants even as they are seated around a conference table. We report on observing six groups of three participants who worked on a collaborative task with minimal assistance. Participants' feedback highlighted the value of MeetAlive features for multi-user engagement in meetings involving brainstorming and content creation. |
 Video: shot and edited by Ines Ben Said Video: shot and edited by Ines Ben Said
Andreas Fender, Joerg Mueller, David Lindlbauer
We present Creature Teacher, a performance-based animation system for creating cyclic movements. Users directly manipulate body parts of a virtual character by using their hands. Creature Teacher's generic approach makes it possible to animate rigged 3D models with nearly arbitrary topology (e.g., non-humanoid) without requiring specialized user-to-character mappings or predefined movements. We use a bimanual interaction paradigm, allowing users to select parts of the model with one hand and manipulate them with the other hand. Cyclic movements of body parts during manipulation are detected and repeatedly played back - also while animating other body parts. Our approach of taking cyclic movements as an input makes mode switching between recording and playback obsolete and allows for fast and seamless creation of animations. We show that novice users with no animation background were able to create expressive cyclic animations for initially static virtual 3D creatures. |
TVCG 2023
Tiffany Luong, Yi Fei Cheng, Max Moebus, Andreas Fender, Christian Holz
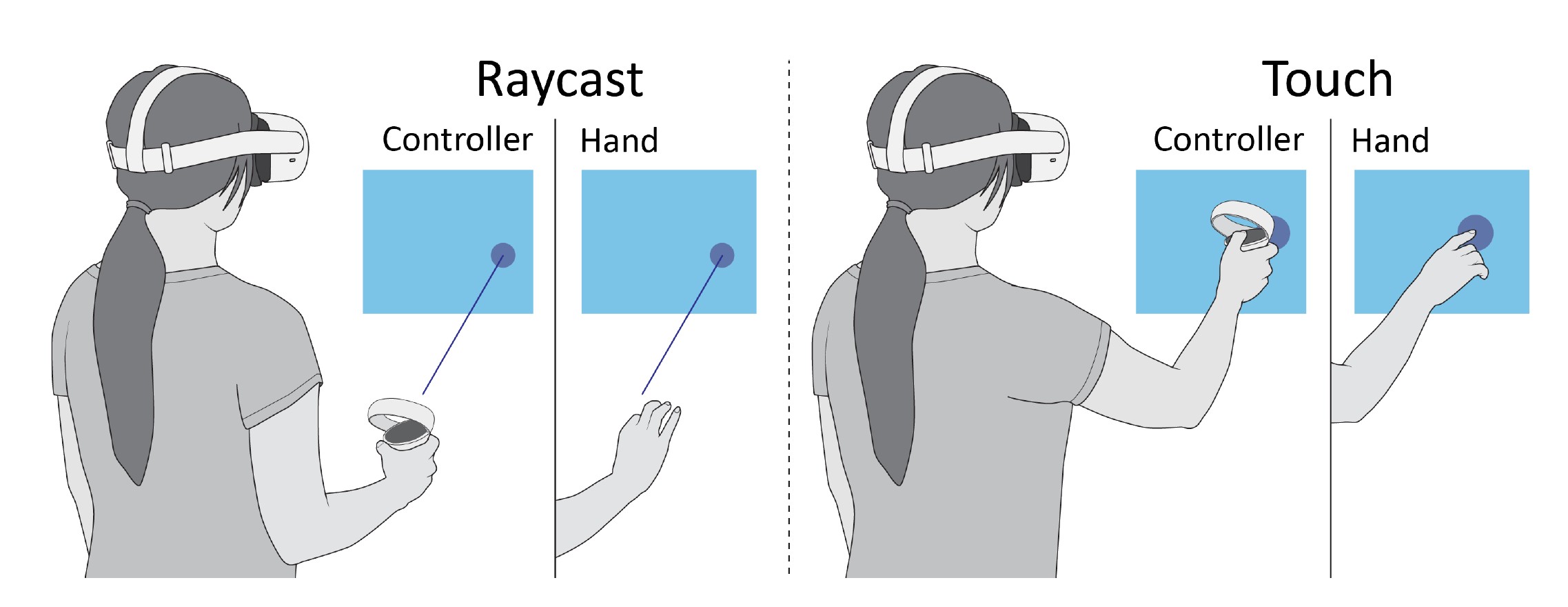
Virtual Reality (VR) systems have traditionally required users to operate the user interface with controllers in mid-air. More recent VR systems, however, integrate cameras to track the headset's position inside the environment as well as the user's hands when possible. This allows users to directly interact with virtual content in mid-air just by reaching out, thus discarding the need for hand-held physical controllers. However, it is unclear which of these two modalities—controller-based or free-hand interaction—is more suitable for efficient input, accurate interaction, and long-term use under reliable tracking conditions. While interacting with hand-held controllers introduces weight, it also requires less finger movement to invoke actions (e.g., pressing a button) and allows users to hold on to a physical object during virtual interaction. In this paper, we investigate the effect of VR input modality (controller vs. free-hand interaction) on physical exertion, agency, task performance, and motor behavior across two mid-air interaction techniques (touch, raycast) and tasks (selection, trajectory-tracing). Participants reported less physical exertion, felt more in control, and were faster and more accurate when using VR controllers compared to free-hand interaction in the raycast setting. Regarding personal preference, participants chose VR controllers for raycast but free-hand interaction for mid-air touch. Our correlation analysis revealed that participants' physical exertion increased with selection speed, quantity of arm motion, variation in motion speed, and bad postures, following ergonomics metrics such as consumed endurance and rapid upper limb assessment. We also found a negative correlation between physical exertion and the participant's sense of agency, and between physical exertion and task accuracy. |
IEEE ISMAR 2022
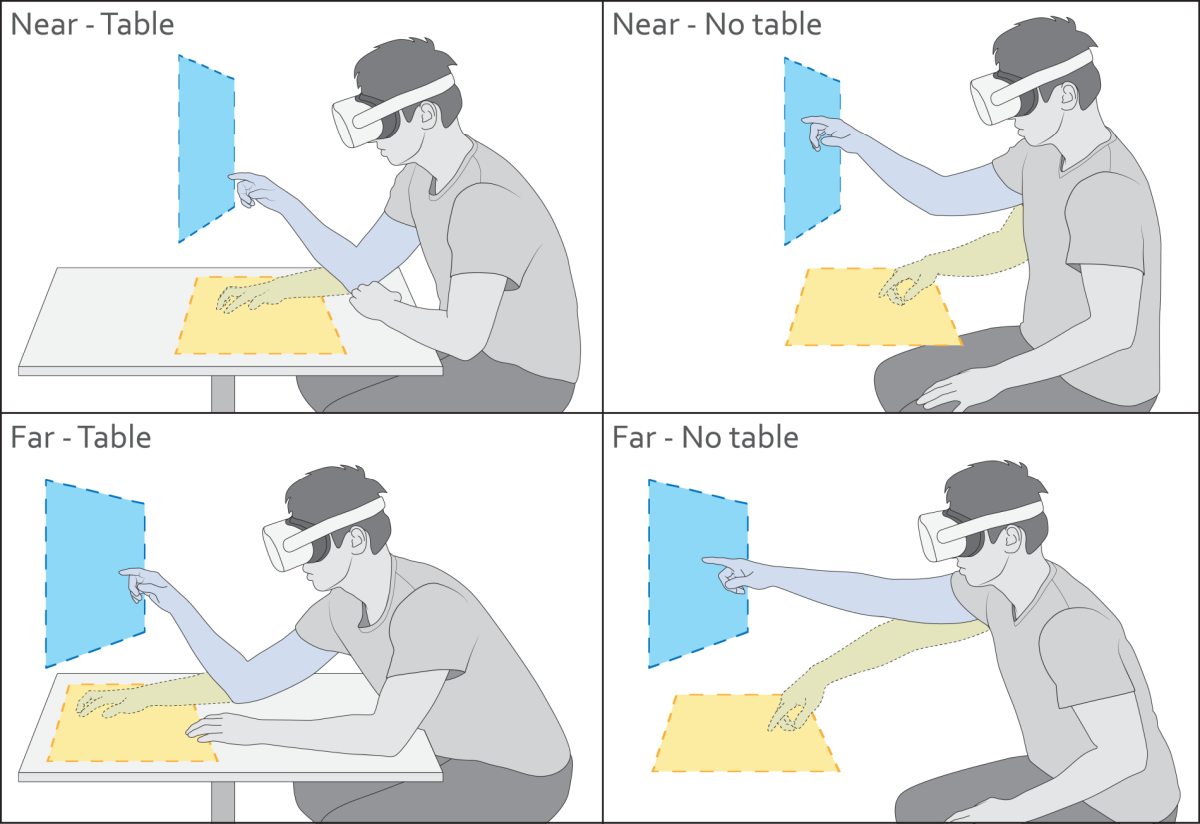
Yi Fei Cheng, Tiffany Luong, Andreas Fender, Paul Streli, Christian Holz
Real-world work-spaces typically revolve around tables, which enable knowledge workers to comfortably perform tasks over an extended period of time during productivity tasks. Tables afford more ergonomic postures and provide opportunities for rest, which raises the question of whether they may also benefit prolonged interaction in Virtual Reality (VR). In this paper, we investigate the effects of tabletop surface presence in situated VR settings on task performance, behavior, and subjective experience. In an empirical study, 24 participants performed two tasks (selection, docking) on virtual interfaces placed at two distances and two orientations. Our results show that a physical tabletop inside VR improves comfort, agency, and task performance while decreasing physical exertion and strain of the neck, shoulder, elbow, and wrist, assessed through objective metrics and subjective reporting. Notably, we found that these benefits apply when the UI is placed on and aligned with the table itself as well as when it is positioned vertically in mid-air above it. Our experiment therefore provides empirical evidence for integrating physical table surfaces into VR scenarios to enable and support prolonged interaction. We conclude by discussing the effective usage of surfaces in situated VR experiences and provide initial guidelines. |
 Video edited by Paul Streli Video edited by Paul Streli
Jiaxi Jiang, Paul Streli, Huajian Qiu, Andreas Fender, Larissa Laich, Patrick Snape, Christian Holz
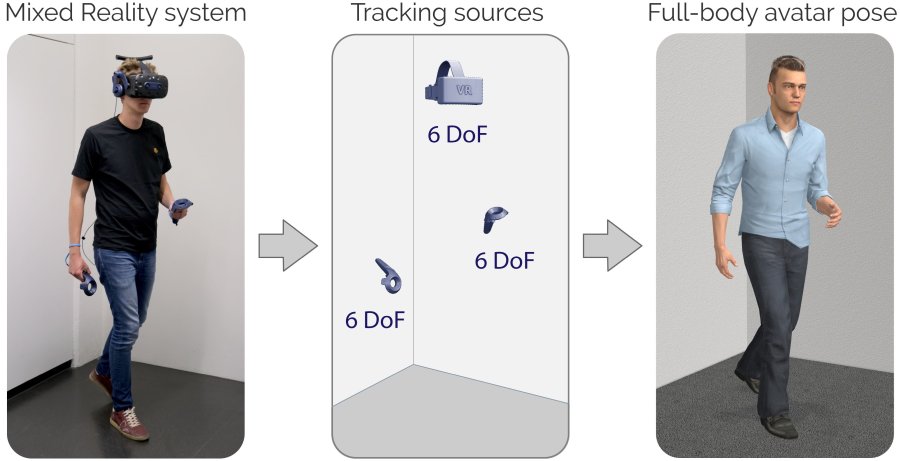
Today's Mixed Reality head-mounted displays track the user's head pose in world space as well as the user's hands for interaction in both Augmented Reality and Virtual Reality scenarios. While this is adequate to support user input, it unfortunately limits users' virtual representations to just their upper bodies. Current systems thus resort to floating avatars, whose limitation is particularly evident in collaborative settings. To estimate full-body poses from the sparse input sources, prior work has incorporated additional trackers and sensors at the pelvis or lower body, which increases setup complexity and limits practical application in mobile settings. In this paper, we present AvatarPoser, the first learning-based method that predicts full-body poses in world coordinates using only motion input from the user's head and hands. Our method builds on a Transformer encoder to extract deep features from the input signals and decouples global motion from the learned local joint orientations to guide pose estimation. To obtain accurate full-body motions that resemble motion capture animations, we refine the arm joints' positions using an optimization routine with inverse kinematics to match the original tracking input. In our evaluation, AvatarPoser achieved new state-of-the-art results in evaluations on large motion capture datasets (AMASS). At the same time, our method's inference speed supports real-time operation, providing a practical interface to support holistic avatar control and representation for Metaverse applications. |
 Video fully created by Mohamed Kari Video fully created by Mohamed Kari
Mohamed Kari, Tobias Grosse-Puppendahl, Luis Falconeri Coelho, Andreas Fender, David Bethge, Reinhard Schütte, Christian Holz
Despite the advances in machine perception, semantic scene understanding is still a limiting factor in mixed reality scene composition. In this paper, we present TransforMR, a video see-through mixed reality system for mobile devices that performs 3D-pose-aware object substitution to create meaningful mixed reality scenes. In real-time and for previously unseen and unprepared real-world environments, TransforMR composes mixed reality scenes so that virtual objects assume behavioral and environment-contextual properties of replaced real-world objects. This yields meaningful, coherent, and humaninterpretable scenes, not yet demonstrated by today’s augmentation techniques. TransforMR creates these experiences through our novel pose-aware object substitution method building on different 3D object pose estimators, instance segmentation, video inpainting, and pose-aware object rendering. TransforMR is designed for use in the real-world, supporting the substitution of humans and vehicles in everyday scenes, and runs on mobile devices using just their monocular RGB camera feed as input. We evaluated TransforMR with eight participants in an uncontrolled city environment employing different transformation themes. Applications of TransforMR include real-time character animation analogous to motion capturing in professional film making, however without the need for preparation of either the scene or the actor, as well as narrative-driven experiences that allow users to explore fictional parallel universes in mixed reality. |